Ember Cluster
Overview
Clients seeking a High Availability (HA) solution can implement Ember Cluster mode. This document describes general ideas and the configuration steps required to build a cluster.
Clients looking for a Disaster Recovery (DR) solution might find the journal replica option to be a simpler alternative. The journal replica asynchronously copies the Ember transaction log to a backup location. While the replica might miss some of the most recent messages and require manual failover, certain clients might opt for this approach over a cluster due to cost considerations. For more information, refer to the Ember Disaster Recovery document.
Highlights
Some highlights of Ember Cluster mode:
- In Cluster mode, Ember uses synchronous write-ahead replication of the system journal (transaction log).
- Ember uses the Kubernetes API or Apache Zookeeper for cluster leader election. There is also a mock leader election mechanism for simple test setups.
- Leader-to-Follower failover is fully autonomous. However, Ember provides the
cluster-cliutility for administrative control.

State
This section explores the state determinism aspect of Ember Cluster. Ember is a platform for both BUY and SELL side trading solutions. These solutions may host anything from pass-through FIX Gateways and quantitative trading strategies to execution algorithms and matching engines.
Ember's approach to state replication is pragmatic determinism: we replicate trading messages (both requests and events), and do NOT replicate external market data and timers. The following subsections explore how this approach applies to various components of the distributed system.
Ember Cluster is designed to not lose a single trading request. Every trading request is replicated before it is processed internally and/or sent to an external execution venue. Each node uses a memory-mapped transaction log that asynchronously persists this information on disk. However, the same cannot be guaranteed for external trading events (e.g., order fills or cancellation events reported to Ember by external execution venues). For more information, see the Data Loss section.
Replication Transport
Ember relies on the Aeron library from Real Logic for its replication transport mechanism. For development purposes, you can run a cluster on a single machine and replicate it using shared memory. The production environment uses the UDP communication protocol (UDP unicast for cloud deployments).
Failover Procedure
In the event of a failover, the follower node performs a set of steps before assuming its new role as the cluster leader:
- The follower node acquires a leadership lock. The cluster coordinator does this by using Zookeeper or K8S Lock.
- Trading Connectors running on the new leader establish connection to execution venues. Up to this point, these trading connectors operate in standby mode, allowing them to accumulate state and monitor outbound sequence numbers and active orders.
- Ember's Order Management System (OMS) issues order status requests for each active order. These requests complete asynchronously.
- The FIX Gateway starts accepting inbound FIX Connections.
It is possible that some FIX clients may connect (Step 4) and request order status information prior to the asynchronous completion of Step 3. However, these “late” order status response messages will also be routed to the respective FIX clients.
Support for the late join of followers has been in place since Ember 1.12.
Limitations
Ember has simplified the graceful shutdown procedure when running as a Follower. No attempt is made to notify algorithms, connectors, message buses, or fix gateways about the upcoming shutdown on the follower node.
Use cases
Trading Algorithm or Execution Algorithm
When implementing your own Trading Algorithm, try to separate the orders and positions in your internal state from those driven by market data. While Positions may have market-driven attributes (like unrealized P&L), it does not mean that the Position state must be a monolith.
In the event of failover, Ember guaranteesm that the follower has seen the same sequence of all trading requests and events. Thus, algorithms running on the follower node should have up-to-date information on open positions and active orders.\
We recomment warming up your market-data portion of the state separately. For example, consider a financial indicator like the Simple Moving Average of the market midpoint price. Both the Leader and the Follower receive live market data and build these indicators independently. The fact that the market data is not replicated may allow some degree of non-determinism in the follower algorithm behavior. However, from a practical standpoint, it is easy to deal with. Deltix has successfully implemented a number of fault-tolerant execution algorithms using this approach, aligned with client specifications.
Replicating ultra-high frequency market data would have provided a more deterministic model. However, factors like replication link bandwidth and trading signal processing latency led to a compromise - to replicate only the trading message flow.
Matching Engine
The Matching Engine is a good example of a state machine. The state of the current order book is completely determined by the sequence of input trading requests, such as order submissions, amendments, and cancellations. This state can be backed up by the sequence of past output events, such as fills and order cancellations. All of these messages are synchronously replicated to the follower.
Risk Processor
Risk Rules are a customizable component that process trading requests and control risk factors ranging from misbehaving trading algorithms to portfolio exposure to external market volatility.\
Let's consider more specific examples:
- Maximum Order Size Limit - Ember replicates risk limit messages that define specific limits for each instrument. Should a failover occur, the follower node is fully capable of resuming the duty of risk checks for future trading requests.
- Maximum Position Size - The Follower node is completely aware of both actual and outstanding positions on each exchange. This awareness is fully driven by replicated trading messages.
- Order Price "Fat Finger" Limit - Ensures that the order limit price, when provided, falls within a certain range of the last known market price. Since the Follower node continues to receive market data even in standby mode, it's primed to initiate checks for this risk limit in the event of a failover.
Data Loss
Any data that is not replicated and journaled runs the risk of being lost. This includes:
Trading Requests in Transmission - For example, a FIX Gateway may receive a TCP packet containing a new order, decode it into an internal message, and then experience a crash before the message is replicated. It's important to note that in this case, the trading order will not be acknowledged back to the client. Following failover, the client can inquire about the status of such an order from the newly elected Leader. Upon such a request, Ember will issue an “unknown order” response in accordance with FIX Protocol.
Trading Events in Transmission - Consider a situation where a FIX trading connector receives a TCP packet containing an order fill, decodes it into an internal message, and crashes before the message is replicated or processed. As part of the failover process described above, Ember will query the order status of all active orders. This information will be used to recover the order state. When multiple fills are reported for a single order during failover, Ember can, at minimum, recover the cumulative size and average fill price.
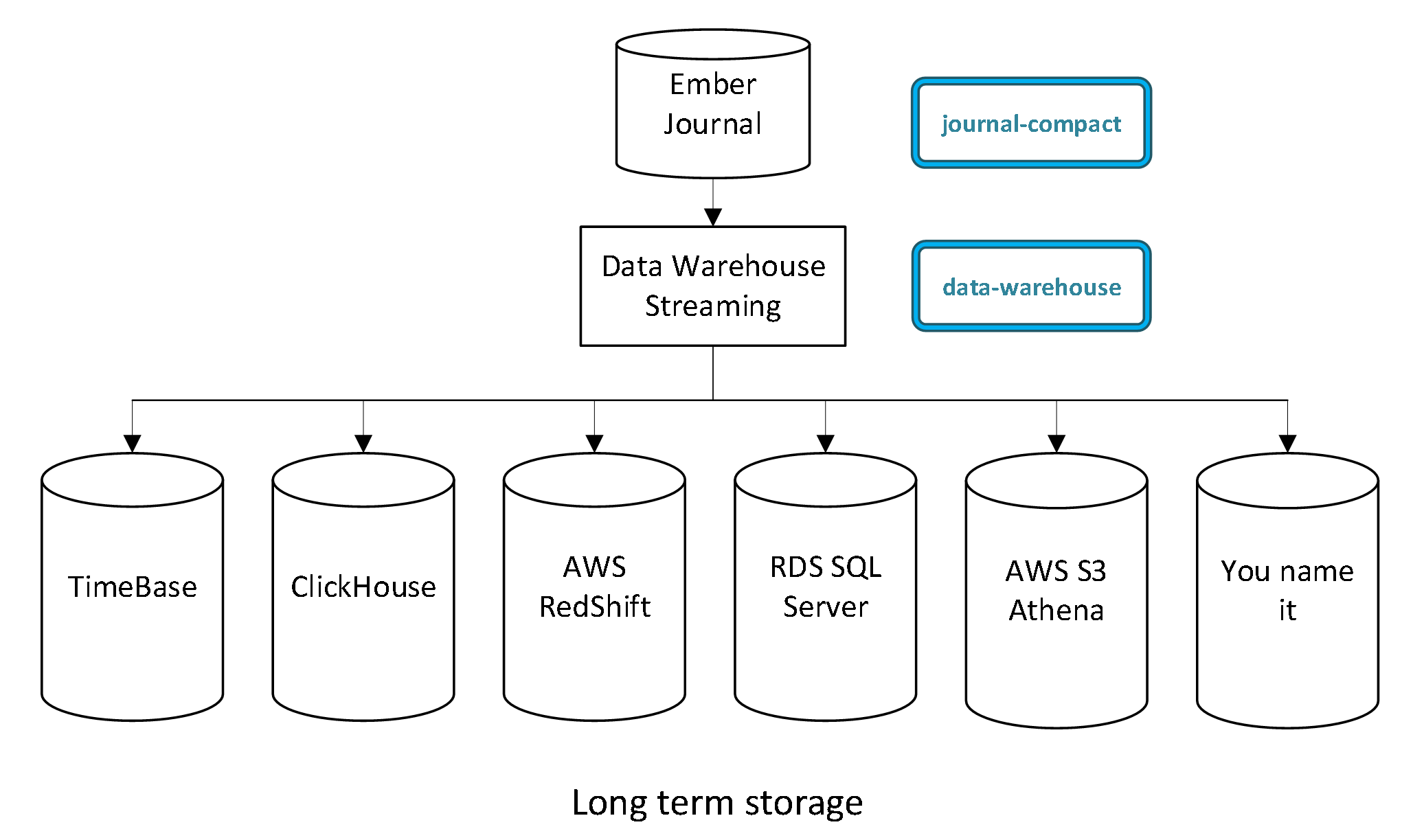
Data Backups
Setup the Ember Data Warehouse pipeline to archive and backup your trading data into a data warehouse of your choice. We currently support TimeBase, ClickHouse, Amazon Redshift, Amazon S3, and Amazon RDS (SQL Server).
These backups will allow you to recover your data in the event that an entire Ember Cluster is lost (e.g., due to a data center outage).
Drop Copy
When running in cluster mode, Ember provides each client two separate FIX Drop Copy sessions. We recommend keeping both FIX sessions active. While both sessions broadcast the same events, at the FIX Protocol level, these sessions are fully independent. For example, the FIX inbound and outbound sequence could easily fall out of sync due to a FIX heartbeat message that might happen on just one of the sessions.
This approach guarantees an “at least once” delivery guarantee for executed trades. On the client side, the Drop Copy should merge information from these sessions by relying on order and execution IDs.
The following diagram shows the Drop Copy setup in a cluster:

The numbers on the diagram indicate the following sequence of steps that takes place when an execution venue reports an order event:
- The exchange reports an order event, such as an order fill.
- The Trading Connector, running on the Leader node, decodes the exchange message and enqueues it into the OMS. Only the leader node maintains an active connection to the execution venue.
- The OMS replicates the message from the Leader to the Follower.
- The fill message is persisted in the Ember journal. This action occurs in parallel on both the leader and follower.
- The Drop Copy service constantly polls the journal (via a memory mapped file region), finds the fill message, and transmits it to the FIX client. This step is conducted in parallel by both the leader and follower nodes.
- FIX Drop Copy clients receive an execution report about the trade from two independent FIX sessions.
In an extreme case, a client might decide to listen to just one of the two Drop Copy sessions from the leader. In such cases, upon the first connection to the follower, the client will receive the entire trade history from the beginning of the Ember journal.
Configuration
The configuration steps are slightly different for Kubernetes and Zookeeper-based leader election. We'll describe both approaches side by side.
Prerequisites
Kubernetes-based Leader Election
If you run the cluster under Kubernetes, no additional software is necessary. Ember will use the K8S built-in mechanism for leader election.
Zookeeper-based Leader Election
If you are running the cluster on bare servers or under Docker Compose, you need to use Apache Zookeeper. Use the following recommended zoo.cfg file (to be placed under Zookeeper's conf directory):
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=c:/projects/zookeeper-3.4.12/data
# the port at which the clients will connect
For production configuration, use a Zookeeper cluster with three or more instances.
Configure Cluster Membership
Kubernetes-based Leader Election
No special steps are required unless you want to manually designate the initial cluster leader. If you want to designate the initial cluster leader, use the cluster-cli utility described in the next section and in Appendix A.
Zookeeper-based Leader Election
The bin directory of the Ember contains the cluster-cli utility that can be used to manage a cluster of Ember nodes.
The following example creates a cluster group named EMBER with the initial leader set to NODE0 (the node ID of one of the Ember instances):
cluster-cli -zk localhost:2181 create EMBER NODE0
For more information about the API of the cluster-cli tool, see Appendix A.
Configure Ember
To configure Ember, place the following configuration stanza into the leader node's configuration files:
cluster {
group = EMBER
node = NODE0
inputChannel = "aeron:udp?endpoint=localhost:19001"
inputStream = 1
outputChannel = "aeron:udp?endpoint=localhost:19002"
outputStream = 2
}
The node ID is different for the follower node, and the input and output channels are reversed:
cluster {
group = EMBER
node = NODE1
inputChannel = "aeron:udp?endpoint=localhost:19002"
inputStream = 2
outputChannel = "aeron:udp?endpoint=localhost:19001"
outputStream = 1
}
Note that the group and node ID can be chosen according to your preference, provided they fit into the ALPHANUMERIC(10) data type.
Next, inform Ember about the leader election mechanism you intend to use.
Kubernetes-based Leader Election
clusterCoordinator {
factory = "deltix.cluster.coordinator.impl.k8s.K8sCoordinatorClientFactory"
settings {
leaseDuration: 10s
renewDeadline: 8s
retryPeriod: 2s
}
}
Zookeeper-based Leader Election
If you use Zookeeper:
clusterCoordinator {
factory = "deltix.cluster.coordinator.impl.zk.ZkCoordinatorClientFactory"
settings {
connectUrl = "zk:localhost:2181"
# Zookeeper session timeout for the coordinator.
sessionTimeout = 10s
# Coordinator startup will fail if connection to ZooKeeper is unsuccessful within the specified time.
startupConnectTimeout = 5s
# If the ZK session is EXPIRED and the ZK client is considered disconnected,
# we will wait this amount of time between attempts to re-create the ZK client in case of failure.
recreationAttemptInterval = 2s
}
}
Mock (Test) Leader Election
For the “MOCK” coordinator (NOT FOR PRODUCTION USE!):
clusterCoordinator {
factory = "deltix.cluster.coordinator.impl.mock.MockCoordinatorClientFactory"
settings {
serverRole = LEADER // or FOLLOWER
}
}
Start Ember
Normal Ember startup looks like this:
/ ____/___ ___ / /_ ___ _____ Version: 0.5.24-SNAPSHOT
/ __/ / __ `__ \/ __ \/ _ \/ ___/ Timebase: 5.2.24
/ /___/ / / / / / /_/ / __/ / Home: /deltix/emberhome
/_____/_/ /_/ /_/_.___/\___/_/ Work: /deltix/emberhome
Copyright (c) 2017-2019 Deltix, Inc.
6 Aug 11:04:19.850 INFO [Thread-3] [TickDBClient] Connected
6 Aug 11:04:21.415 INFO [main-EventThread] CONNECTED to ZK
6 Aug 11:04:23.254 INFO [replicator] Replicator changed state from INITIAL to REGISTERING.
6 Aug 11:04:23.263 INFO [coordinator] Registered node NODE0 in group EMBER
6 Aug 11:04:23.264 INFO [coordinator] Coordinator changed state from INITIAL to WAIT_READY.
6 Aug 11:04:23.264 INFO [replicator] Replicator changed state from REGISTERING to BOOTSTRAP.
6 Aug 11:04:23.541 INFO [clustered-service] Clustered service worker changed state from INITIAL to REPLAYING.
6 Aug 11:04:23.542 INFO [clustered-service] Clustered service worker changed state from REPLAYING to DUTY_CYCLE.
6 Aug 11:04:23.543 INFO [replicator] Replicator changed state from BOOTSTRAP to CANDIDATE.
6 Aug 11:04:24.143 INFO [coordinator] Group EMBER was updated successfully updated
6 Aug 11:04:24.144 INFO [coordinator] Cluster role for nodeId=NODE0 in groupId=EMBER is LEADER_WITH_FOLLOWER
6 Aug 11:04:24.144 INFO [coordinator] Cluster role for node EMBER:NODE0 is LEADER_WITH_FOLLOWER
6 Aug 11:04:24.145 INFO [replicator] Replicator changed state from CANDIDATE to LEADER_WAITING_FOR_ FOLLOWER.
6 Aug 11:04:24.146 INFO [coordinator] Coordinator changed state from WAIT_READY to WAITING_FOR_FOLLOWER.
6 Aug 11:04:32.563 INFO [replicator] Replicator changed state from LEADER_WAITING_FOR_FOLLOWER to LEADER_WITH_FOLLOWER.
6 Aug 11:04:32.565 INFO [coordinator] Coordinator changed state from WAITING_FOR_FOLLOWER to LEADER_WITH_FOLLOWER.
6 Aug 11:04:32.596 INFO [algorithm-NIAGARA] Algorithm NIAGARA switched from CANDIDATE to LEADER role
6 Aug 11:04:32.597 INFO [marketdata-gwy-sess-MGW1] Market Gateway MGW1 switched from CANDIDATE to LEADER role.
6 Aug 11:04:32.616 INFO [trade-gwy-trans-TGW1] Gateway TGW1 resumed accepting new connections
6 Aug 11:04:32.633 INFO [trade-gwy-sess-TGW1] Trade gateway TGW1 switched from CANDIDATE to LEADER role.
6 Aug 11:04:35.030 INFO [trade-gwy-trans-TGW1] Gateway TGW1 accepted connection on port 12001 from /10.0.0.215:48908 as session TUSER1 (TUSER1) (Conn id: 2844687108211914240)
Advanced Topics
Healthcheck
The Ember service can provide an optional healthcheck port. For example, the following configuration stanza enables healthcheck on port 9000:
network.healthcheck {
host = 0.0.0.0
port = 9000
}
In the current version of Ember, only the leader’s Ember instance will respond to a healthcheck. When a follower becomes a leader, it also activates the healthcheck port listener.
Leader Election
Ember offers several implementations of leader election: Kubernetes-backed, Apache Zookeeper, and a simplified mock implementation more suitable for test setups.
The Kubernetes and Zookeeper-based implementation rely on a distributed lock. The leader node obtains the lock and maintains it during runtime. A follower node attempts to capture the lock. When the lock is captured, it signifies that the previous leader is inactive.
An abstract distributed lock needs one adjustment to be practically useful. It's important to ensure that the leader always has the most recent state, which is stored in the Ember journal. For this reason, the leader election mechanism is adjusted so that a follower cannot become a standalone leader on startup:

The follower node obtains the ability to become a future leader only after successfully joining the current leader and synchronizing the trading state. This approach prioritizes a consistent trading state over availability.
There may be situations when an entire cluster dies, and the last leader is unrecoverable due to factors like hardware failure. In such cases, trading would need to be resumed using an ex-follower’s journal. During this exceptional situation, attempting to cold start the cluster without the previous leader will require manual intervention. Use the cluster-cli tool to erase information about the fallen leader.
Replicator
The following diagram illustrates Replicator states:

Cluster Coordinator
Ember uses an abstraction layer called the “Coordinator” to support different leader election implementations (such as K8S Leader Lock, Apache Zookeeper, etc.).
The Coordinator is a state machine that supports the following transitions:

A few noteworthy points:
- Ember uses coordinators that can reliably store the current leader's identity and preserve information about the last leader when the cluster is down.
- If a leader loses its connection to the election mechanism (due to connection loss or an excessively long GC pause, for example), you can force it into the CLOSED state and terminate it.
- A follower can only become a leader after syncing with the previous leader.
Appendix A: Cluster CLI API
This section describes the API of the cluster-cli tool.
To view the current cluster state, use the info command:
cluster-cli -k8s info EMBER
To update the cluster state, use the update command:
cluster-cli -k8s update EMBER NODE1
If you use Kubernetes for Ember leader election, you must supply the -k8s command line argument. Alternatively, you can use the –zk argument followed by the Zookeeper connection URL:
/deltix/ember/bin/cluster-cli -zk 10.0.1.65:2181 info EMBER
zkhost: 10.0.1.65:2181
Connecting to ZooKeeper...
2021-09-20 21:11:14.689 INFO [main] Initiating client connection, connectString=10.0.1.65:2181 sessionTimeout=3000 watcher=deltix.cluster.coordinator.impl.zk.clustertool.ClusterControlTool$1@5f375618
2021-09-20 21:11:14.769 INFO [main-SendThread(10.0.1.65:2181)] Socket connection established, initiating session, client: /10.0.1.58:57030, server: ip-10-0-1-65.us-east-2.compute.internal/10.0.1.65:2181
2021-09-20 21:11:14.777 INFO [main-SendThread(10.0.1.65:2181)] Session establishment complete on server ip-10-0-1-65.us-east-2.compute.internal/10.0.1.65:2181, session id = 0x1000008a2920003, negotiated timeout = 4000
Connected to ZooKeeper
Group EMBER info:
LEADER = (none)
initialLeaderNodeId = NODE0
lastLeaderNodeId = NODE1
Active nodes:
(none)
For reference, here is an example of invoking the cluster-cli utility from Docker:
docker run --entrypoint "/opt/deltix/ember/bin/cluster-cli -zk 10.0.1.65:2181 info EMBER" -it packages.deltixhub.com/deltix.docker/anvil/deltix-ember:1.9.12
Appendix B: Kubernetes-based Leader Election
The current version of Kubernetes-based leader election uses a leader election-based ConfigMapLock. Once lock ownership is confirmed, the leader node writes its identity into the underlying config map under the “leader” key. In the following example, we can see that the config map (currently locked by ember-1 according to the holderIdentity annotation attribute) has the “leader” attribute set to ember-1.
>kubectl describe configmap ember-cluster
Name: ember-cluster
Namespace: default
Labels: <none>
Annotations: control-plane.alpha.kubernetes.io/leader:
{"holderIdentity":"ember-1","leaseDurationSeconds":10,"acquireTime":"2022-08-09T15:28:18.063Z","renewTime":"2022-08-09T16:16:53.096Z","lea...
Data
====
leader:
----
ember-1
BinaryData
====
Events: <none>
To erase the last cluster leader, use the following command. Please note that the cluster must be stopped):
curl -X DELETE '[http://192.168.56.200/apis/v1/namespaces/default/configmaps/ember-cluster'](http://192.168.56.200/apis/v1/namespaces/default/configmaps/ember-cluster')
Here, 192.168.56.200 represents the address of the kube-apiserver.
Appendix C: Cluster Configuration Settings
The following block shows advanced cluster configuration parameters that can be tuned in ember.conf:
cluster {
startupTimeout = 60s
livenessTimeout = 5s
connectInterval = 1s
heartbeatInterval = 1s
}