Ember High Availability and Disaster Recovery
Overview
This section provides an overview of the capabilities of the Ember and explains some of the design choices made. The main content of this document describes the available High Availability (HA) and Disaster Recovery (DR) options for Ember users.
High Availability
The term High Availability (HA) is sometimes surrounded by marketing hype, so it's important to establish clear terminology before delving into the various operational modes of Ember. According to Wikipedia, "High Availability is a characteristic of a system which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.”
The normal operation of the Ember does not require periodic downtime. We hace clients who run Ember 24/7 for months on end without requiring restart, even while processing millions of orders daily. However, occasional restarta are required to apply major configuration changes or perform system version upgrades. Such events can be strategically planned and performed during non-market hours.
Unplanned interruptions are also a consideration. To guard against hardware failures, disruptions in cloud infrastructure, or software issues, Ember employs redundant service instances. Trading signals that affect mission critical data are replicated between these instances. The Ember supports both synchronous and asynchronous replication--from the leader server instance to the follower instance.
Fault Tolerance
Fault tolerance refers to a system's capacity to continue functioning correctly even when some of its components fail. The well-known CAP Theorem states that in the event of a failure in a distributed system, it can either prioritize consistency (C) or availability (A), but not both simultaneously. Since strong consistency (C) of the trading state (orders, positions, and their impact on risk and exposure) is a strict requirement in the trading domain, the implication of the CAP Theorem is that a distributed trading system cannot achieve 100% availability (A).
The CAP Theorem specifically refers to Partitioning (P) failures. When applied to small clusters, e.g., Leader/Follower, this can mean a failure of one of the Ember instances.
Some additional factors to consider:
- A key function of the Ember is the ability to process trading signals for financial markets. For example, trade orders issued by alpha-seeking algorithms to external markets like CME, as well as fills and order cancellation events emitted back from CME. Given that trading signals are extremely time-sensitive, particularly in the realm of high-frequency trading (HFT), synchronous replication may not be a practical choice, especially when replication spans different geographical locations.
For example, the latency between a co-location data center and the nearest cloud availability zone typically spans tens of milliseconds. Such high latency makes it impractical to use synchronous replication for trading signals. By the time the signal is copied to the cloud and acknowledgement is received, the signal could be too late for the market.
- When Ember operates as a smart gateway to external execution venues, the downstream APIs' HA capabilities impact Ember's availability Service Level Agreement (SLA). Most execution venues offer APIs that require some form of failover procedure to recover the state of recent orders in case of interruption. This failover procedure usually takes several seconds to execute, even when fully automated. Consequently, Ember operates at a reduced functionality level during downstream API failover events.
System State Durability
Orders, Trades, and Positions
Ember uses an event sourcing approach to maintain trading state. Trading signals, encompassing trading requests and events received as responses from execution venues, are stored in a local journal.
The Ember Journal Compactor works in cooperation with the data warehouse and is responsible for keeping the journal size on disk within a configurable limit.
The trading state can be deterministically reconstructed from the sequence of trading signals. To extend local journal durability, two options are available:
- You can establish an Ember Cluster that will synchronously replicate trading signals from the Leader Ember instance to the Follower instance. In the event of a failover, the Follower instance will establish the precise trading state, including the most recent order requests, and synchronize the state of these orders using execution venue APIs.
- You can set up asynchronous replication of the journal to a Disaster Recovery (DR) location. This replication can be an exact binary replica of the Ember Journal or a third-party Data Warehouse, such as Amazon S3 or ClickHouse.
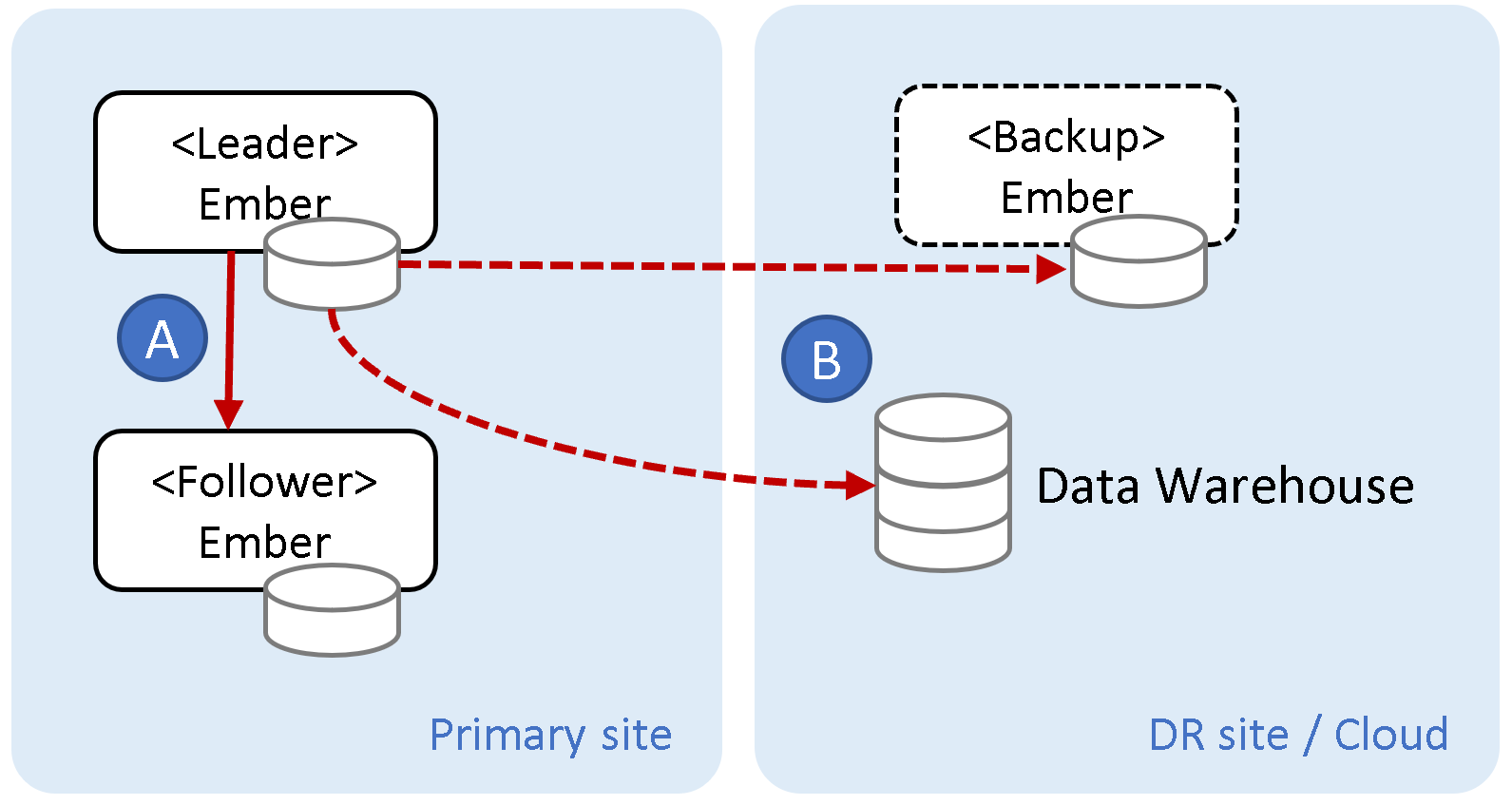
It is worth mentioning that these two state replication methods are not mutually exclusive. They can be complementary. Clients can implement both approaches (A and B) in the same setup.
The following table provides a comparison of these two options:
| Approach | Ember DR | Ember Cluster |
|---|---|---|
| Scope | Multiple data centers, possibly in different regions | Single data center, same network |
| Recovery Time Objective | 1-3 hours | Seconds to a few minutes |
| Data Replication method | Asynchronous, Batched | Synchronous |
| Data loss in case of a disaster | Depends on batch size and replication method. May lose several minutes of recent trading activity. | No order loss for trading requests. Possible loss of exact information about each trade (only cumulative/average trade information may be recovered). |
| Operational Complexity | Manual failover. Some DevOps work to set up files replication. Some upfront cost to set up journal replicator. | Fully automated failover. There is some additional cost to maintain and host additional cluster services (Aeron, Zookeeper, Journal sync). |
| Hardware/ Cloud Hosting Cost | DR location can provision most expensive resources on demand (in case of failover). | Requires 2x resources compared to single-instance Ember setup. In addition to Leader + Follower instances, Ember Cluster requires an additional instance to host Kubernetes control plane or Apache Zookeeper that functions as a cluster arbiter (to remedy “split brain” situations). |
Connectivity to Execution Venues
Establishing HA connectivity to downstream execution venues presents a special challenge. Few venues provide fault-tolerant APIs, meaning that in the event of a failure, the trading state on the Ember side may temporarily be out of sync with the Execution Venue (usually for a few seconds following re-connect).
In Ember Cluster mode, we recommend configuring the leader and follower with independent connection credentials. During regular cluster operations, only the leader Ember instance is connected to the execution venue. The follower instance receives copies of all trading requests and events that flow through the leader instance (in case the connector needs to maintain some state). In the event of a failover, the newly elected leader will establish its own connection and perform a synchronization procedure for all recent orders. Since the ex-follower instance receives copies of all trading signals, it knows the state of orders that need synchronization. For more information, see the Ember Cluster document.
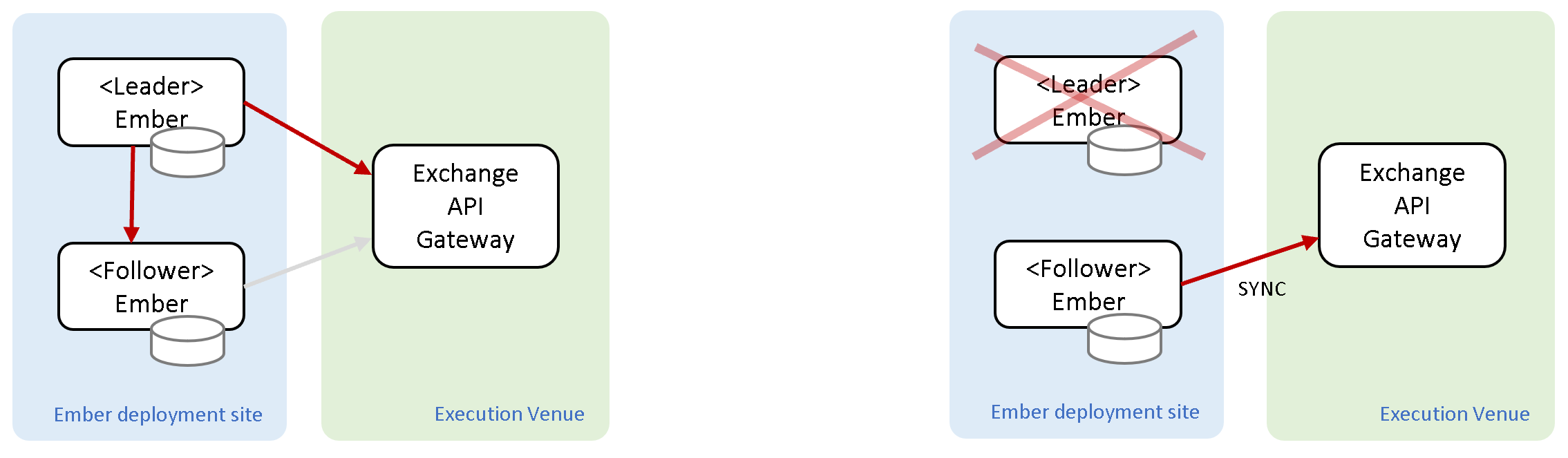
The same principle applies to Ember DR mode: independent connection is recommended. The DR instance of Ember only establishes exchange connections in the event of a failover. Since DR relies on asynchronous replication, there is a possibility that the most recent orders placed by the failed leader will be unknown at the DR location. For more information, see the Ember DR documentation.
Ember Trading Connector settings allow specifying backup gateways or IP addresses when execution venues provide them.
Market Data
Ember uses Deltix TimeBase to deliver market data to the system. While TimeBase can be used to achieve data durability, this choice comes with higher costs, including increased market data latency and additional hardware resource consumption. To reduce latency, TimeBase distributes market data to live consumers prior to storing it. Unless you are required to reliably keep market data that you feed to Ember, we recommend running a dedicated Timebase for each Ember instance, as shown in the diagram below, on the left side (Active/Active setup):

Should one of the TimeBase instances experience a failure, you may take down the associated Ember instance or failover to another instance. Once failed TimeBase instances comeback online, missing data can be backfilled (in the case of gapless historical market data, this is required). However, backfilling and maintaining the quality of historical market data typically isn't a concern for real-time trading algorithms. These algorithms need the most recent market data and never pause to wait for backfill.
Ember algorithms are aware of the non-deterministic nature of market data. Algorithm developers take measures to separate data structures that describe trading activity (orders, positions, etc.) from data structures that are driven by market data (financial indicators, market trends, etc.).
If you have special requirements to preserve the exact market data that influenced trading logic, one approach is illustrated in the diagram below. The idea is that Ember consumes market data from a replica TimeBase instance. This redundant TimeBase instance approach is more complex to support and introduces an additional latency of around 100-200 microseconds (assuming a local network connection).

TimeBase replication can be configured per stream and setup to run in near real-time or in periodic batches.
Important data can be archived to data warehouse like Amazon S3. More options are described here.
TimeBase 6.0 has built-in support for recording data with a configurable replication factor. However, due to the additional latency overhead, we do not recommend this mode for market data broadcasting.
Deployment Options
This section describes several typical deployment scenarios.
Baseline (Single Instance)
Before delving into HA/DR options, let's consider a baseline scenario – employing a standalone Ember instance in the cloud.
The contemporary infrastructure-as-code approach makes it easy to redeploy Ember on another machine. Deltix provides integrations with Kubernetes, Docker-compose, and Ansible that allow the redeployment of both code and configuration files in a matter of seconds.
When combined with durable storage for operational data (Ember Journal + logs) that survives instance degradation and a data warehouse pipeline acting as a reserve copy of trading history, even a single-instance cloud deployment can offer decent DR characteristics.
Amazon's iops2 EBS volumes provides 99.999% durability at a relatively low cost compared to an HA setup.
Single Data Center
In some cases, business requirements dictate the establishment of a reliable installation within a single data center, e.g., in proximity to a specific market. In such cases, connectivity at a DR location may not make sense, as the system can’t operate without direct access to the marketplace.
In this case, the HA design calls for the adoption of an Ember Cluster. Additionally, the trading state can be backed up to a data warehouse. The diagram below illustrates AWS S3 as the data warehouse, but the choice isn't confined to AWS alone. It could encompass any of the supported data warehouses, potentially even hosted in a different network within the same data center.
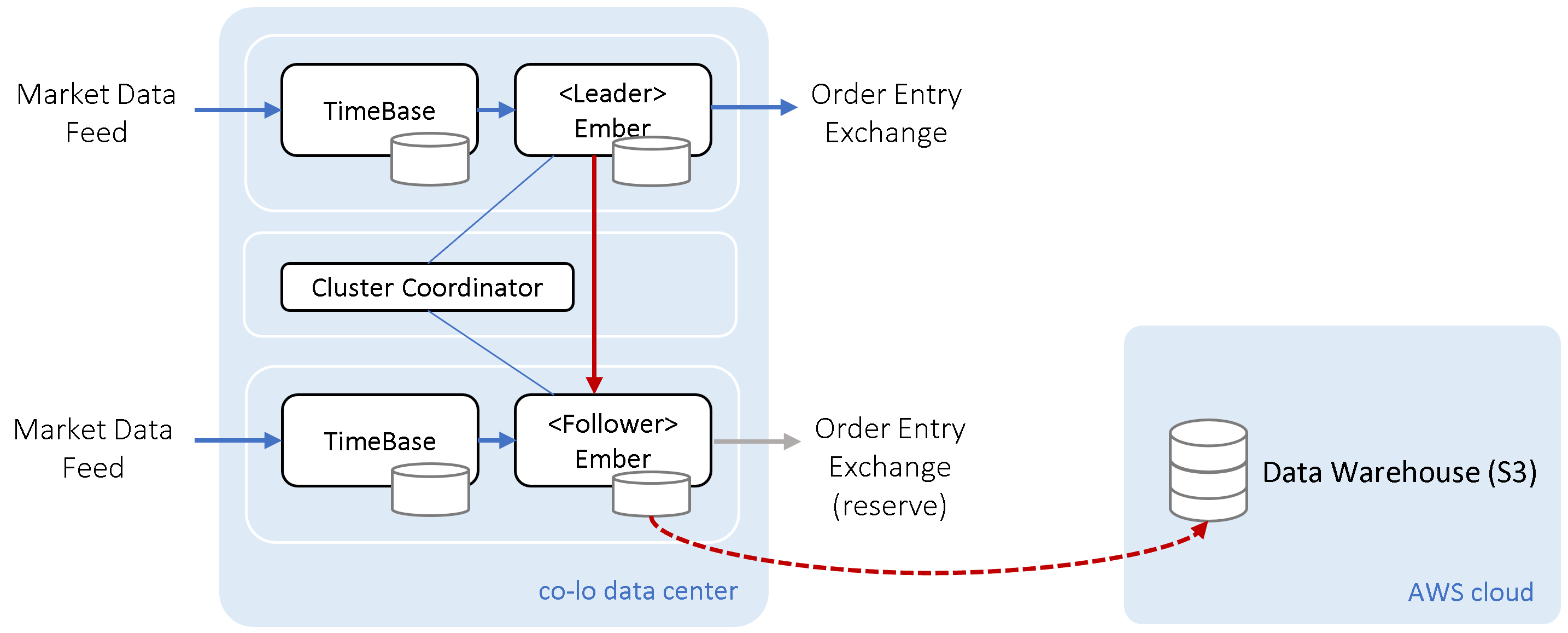
Data Center with Cloud Backup
Another deployment option is having a standalone Ember setup running on-premises with cloud backup. This setup makes sense in scenarios where backup exchange connectivity is available via the cloud.
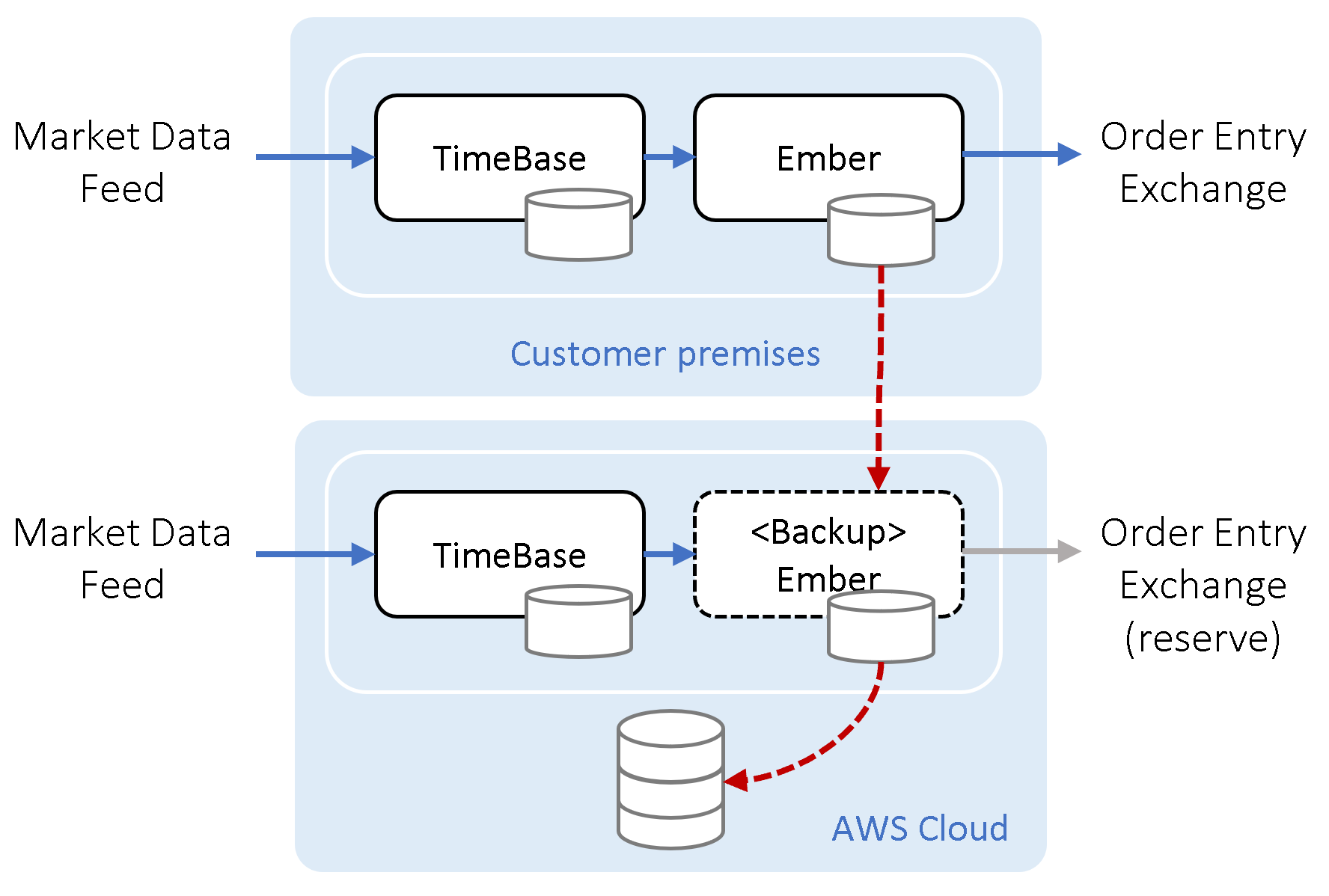
Cloud Only
Most crypto exchanges are cloud-native. When trading on crypto exchanges, we recommend the cloud-only setup.
The diagram below shows a composite HA design: the primary availability zone runs an Ember Cluster, while an asynchronous replica is made into a separate availability zone (where a hot TimeBase is hosted alongside a cold or warm Ember).
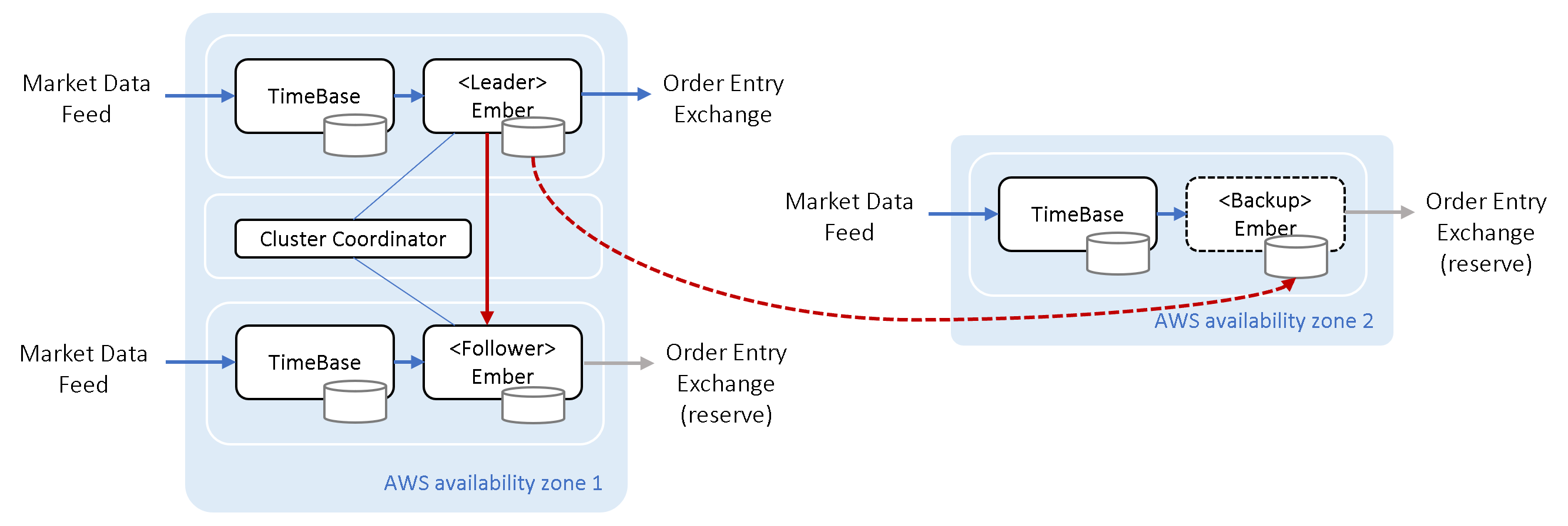
Conclusion
This document describes several generic HA/DR options for Ember deployment. Naturally, an optimal HA solution for auto-trading robots on CME will vastly differ from an HA solution that performs smart order routing. An Ember-based implementation of a digital currency exchange calls for yet another HA architecture. We recognize that different business models have different requirements and constraints. Deltix is happy to design a customized HA/DR architecture for each unique case.