Ember Journal Deep Dive
Author: Artyom Korzun
Overview
Ember uses a write-ahead logging mechanism for trading signals. This document describes the format of the Ember Journal, also known as the transaction log.
Ember 1.0 introduced a new format for the system journal that offers several considerable improvements:
- Support for Snapshots - Snapshots significantly speed up the restart time for Ember itself and all downstream services like Monitor and Data Warehouse.
- Data Partition Files - Instead of a single monolithic file, the new format introduces data partition files. These files allow the system to be configured to automatically and safely delete “old” partition files, optimizing storage management. Additionally, this procedure tracks journal consumers, such as a data warehousing service, ensuring that slow consumers will not lose data.
Journal Directory Structure
The journal is a transaction log that stores the history of trading operations. It lives in the Ember work directory under the journal directory and consists of three types of files: meta, data, and snapshot files.
- The meta file contains “metadata” information that is used by the journal for ensuring data integrity and maintaining operation consistency.
- The data file is a sequential partition of data with a fixed maximum size. By default, the size of each data file is 1 GB. When a data file is filled, a new one is created to continue recording further transactions.
- A snapshot file contains a copy of messages that represent the current trading state at a specific point in time, serving as a point-in-time representation of the trading system's state and enabling efficient state recovery and analysis.
Snapshotting
Ember implements a state machine and the journal data files record all events that change this state. As time goes by, some of these events become non-essential for state recovery. For example, there is no need to retain a trade order that existed many weeks ago and never got filled.
During run time, Ember keeps the following trading state in memory:
- All active orders
- Last N completed orders for each client
- Positions and risk rules state
The Data Warehousing pipeline can be configured to record all trading orders and events into long term storage.
As the system runs, past fills are compressed into position sizes in Ember’s memory.
Snapshot files store a copy of messages that recover the current trading state. Each subsequent snapshot includes new orders and may remove some completed orders. It helps speed up the restart time for Ember and downstream services.
Important: Please never delete or modify any of the journal files manually. Indexes on data files and snapshot files are not directly related. Only the “compactor” tool described below should be used to manage files in the journal directory.
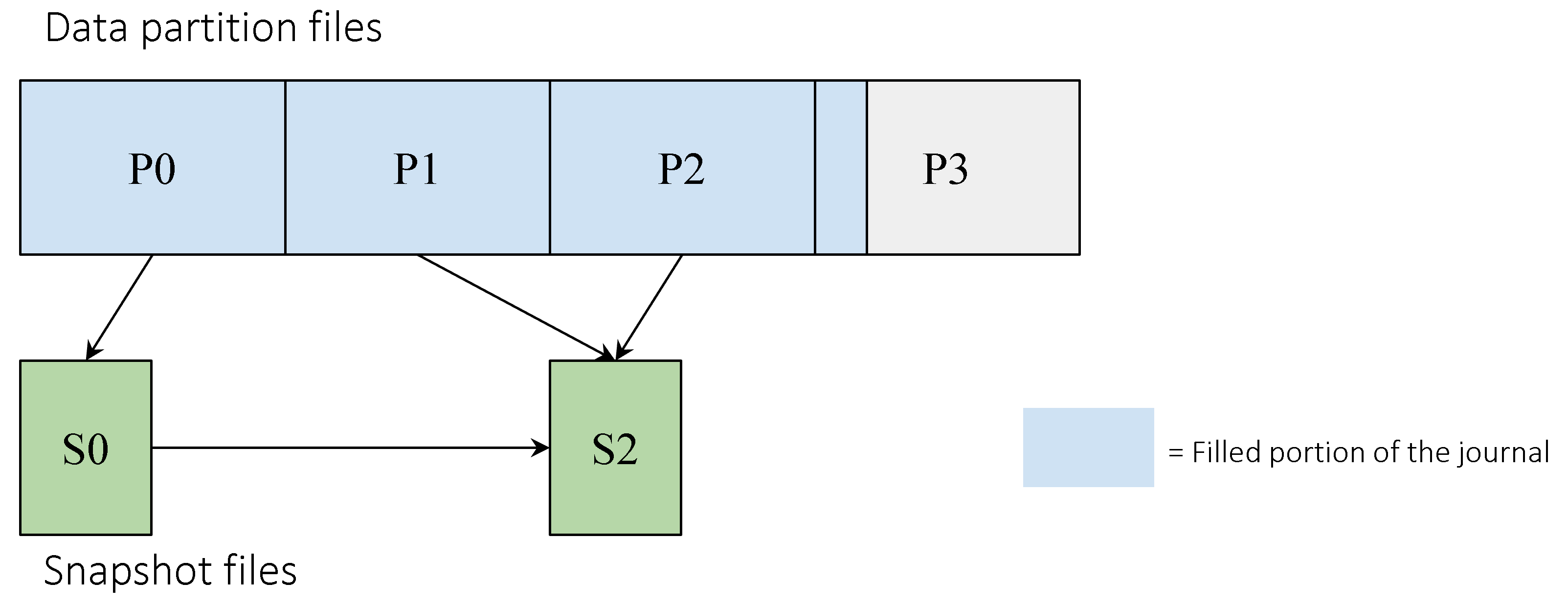
A typical journal directory structure might look like this:
- meta
- data0
- data1
- data2
- data3
- snapshot0 (contains the data from data0)
- snapshot2 (contains the data from snapshot0, data1 and data2)
This directory content can be illustrated using the following diagram:
Here is another example showing the content of a journal directory from one of Ember's stress tests:
[centos@ip-10-0-0-62 ~]$ ls -l /deltix/emberhome/journal/
total 3700960
-rw-r--r-- 1 centos centos 1073741824 Apr 10 15:27 data11613
-rw-r--r-- 1 centos centos 1073741824 Apr 10 15:28 data11614
-rw-r--r-- 1 centos centos 1073741824 Apr 10 15:29 data11615
-rw-r--r-- 1 centos centos 545259520 Apr 10 15:29 data11616
-rw-r--r-- 1 centos centos 1792 Apr 10 15:28 meta
-rw-r--r-- 1 centos centos 23291024 Apr 10 15:28 snapshot11613
-rw-r--r-- 1 centos centos 256 Apr 10 15:29 snapshot11615.16297.temp
Here you can see that each data file is 1Gb in size. The system automatically deleted datafiles 0 - 11612 since they already have already been recorded into snapshot 11613. The snapshot for this particular trading history took approximately 23 megabytes, as the system had about 30K active orders.
Warehousing
A journal grows constantly over time, especially with a high operation rate. On startup, Ember replays the entire journal to restore the system state. However, some data, like old inactive orders, may no longer be needed and can be removed to reduce the journal's size. This filtered content can be saved as a separate “snapshot” file.
If there are snapshots on startup, Ember loads its state from the latest snapshot and then reads partitions after it. This approach dramatically reduces startup time. Ember satellite processes, such as Ember Monitor or Data Warehouse, also benefit from using snapshots.
You can set up the Data Warehouse service to stream the journal to a data storage system in order to save the entire trading history and perform post-processing on the data. This way, partitions can be safely removed from the journal, but the data will live in another place.
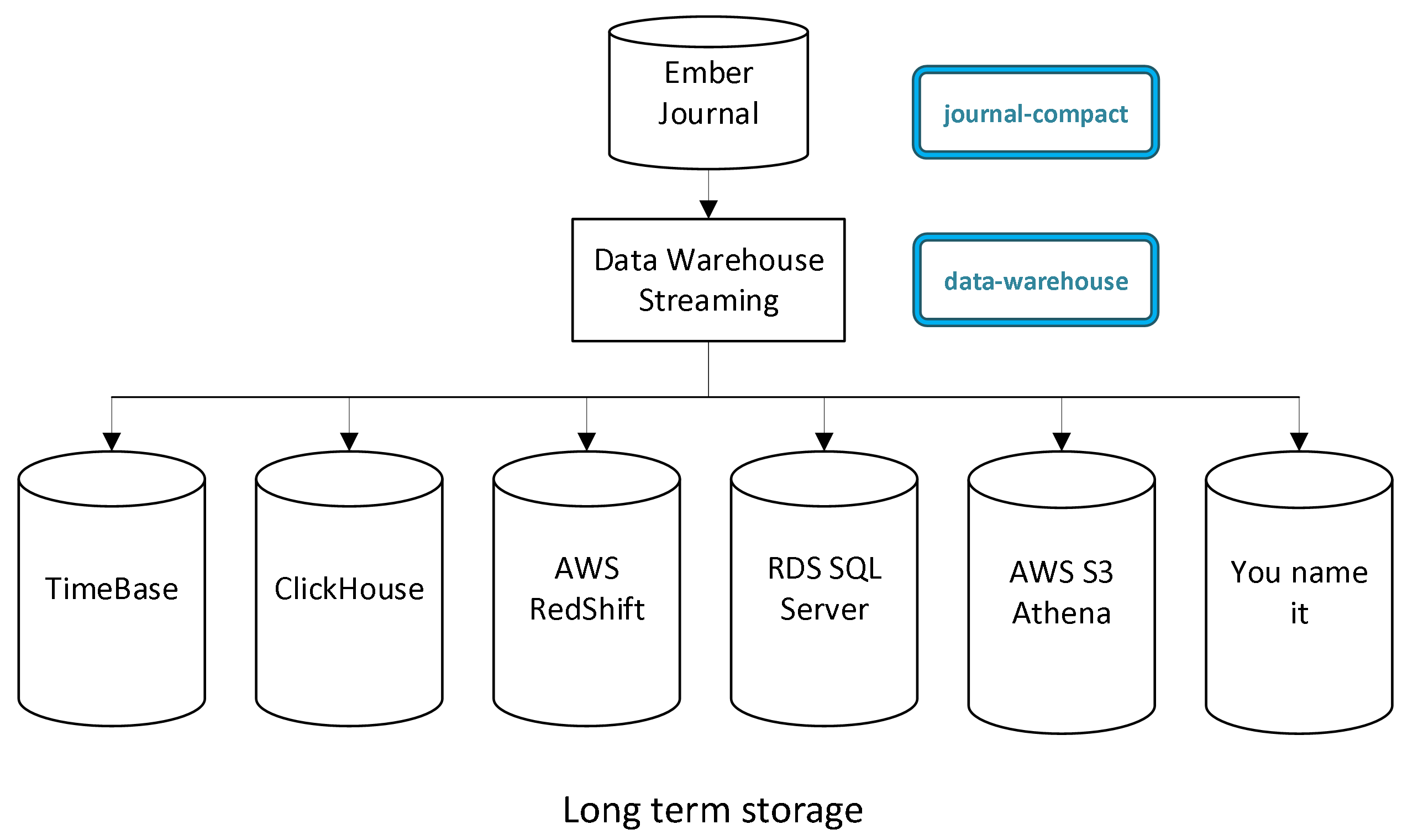
For more information about Data Warehouse solutions, see the Data Warehouse document.
Compaction
The Compactor is a background service that can take snapshots and delete old snapshots and partitions. You can find the journal-compaction script in the Ember distribution package.
Configuration Settings
The script has the following settings in ember.conf:
compaction {
# Automatically delete “old” data partitions
# if you do not need to preserve full operation history on a disk
deletePartitions = false
# Keep at least N of the last snapshots (min is 2)
keepSnapshotsAtLeast = 2
# null means auto-discovery or use explicit file paths like ["a", "b"]
fences = null
# Sleep period between checks for taking a new snapshot and deleting old files
idlePeriod = 1m
}
Historical trading data retention
Note that deletePartitions is false by default - this means data partitions will not be automatically deleted (and eventually you may run out of disk space). We strongly do not recommend deleting data files manually - let the compactor do this.
This option is off by default as a safety measure. Usually brand new systems do not have long term data warehousing set up and keeping all existing trading history seems like a safer alternative.
On the other hand, once you have a data warehouse set up (e.g. store trading history to AWS S3) we do recommend setting deletePartitions to true.
Historical snapshots
Once automatic removal of data partitions is enabled, parameter keepSnapshotsAtLeast will control the footprint of the ember journal directory on disk.
For example, setting keepSnapshotsAtLeast to 10 means the compactor will keep the last 10 snapshots and all data files required to reload trading history from the earliest snapshot. This means 10+1 data files (+1 is the active data partition that will get a snapshot once it is completely filled) and 10 snapshots.
Default data file size on disk is 1 GB, typical snapshot size is 100 MB. Hence for keepSnapshotsAtLeast set to 10, you can expect your journal directory to be around 12 GB.
Fences
Fences are positions of each data warehouse in the journal. Each reflect journal message sequence number up to which trading history has been saved to specific data warehouse instance. Journal compactor can't delete data partitions if there are fences pointing at it.
- Fence files are written by journal readers (DropCopy, TimeBase Data Warehouse, etc.), not by the compactor
- Auto-discovery is the default: if compaction.fences is null/absent, the compactor scans the config for
dropCopy,fsra,fixStoreGateway, and allwarehouse.*units and reads the fence path from each. - Manual fence list in above config stanza overrides discovery entirely — no mixing
- The compactor waits for fence files to exist before starting (consumers must create them on first run)
- Deletion is blocked at the minimum fence partition across all consumers — the slowest consumer controls how far compaction can proceed
- If you remove a service from config, you must manually delete its fence file, otherwise it will perpetually block compaction (the file exists but never advances)
Command line
The Journal Compactor typically requires Ember to be running, as it waits for Ember to become ready on startup. However, in some cases (such as at a DR site) it may be beneficial to run the Compactor without the Ember service. In such scenarios, the -nowait command-line argument can be used to bypass the Ember readiness check at startup. The -skip-heartbeat command-line argument can be used to skip Ember heartbeat liveness check, verifying only lock file presence.
Additionally, it may be necessary to ignore all fences from all warehouses when running the Compactor, allowing it to delete partitions regardless of warehouse positions. To do this, use the -ignore-fences command-line argument.
Using -ignore-fences while warehouses are running may cause them to fail, as the Compactor may delete partitions that warehouses have not yet processed.
Since version 1.15.9, all command-line arguments should be written in camelCase. For example: use -skipHeartbeat instead of -skip-heartbeat, -ignoreFences instead of -ignore-fences, etc.
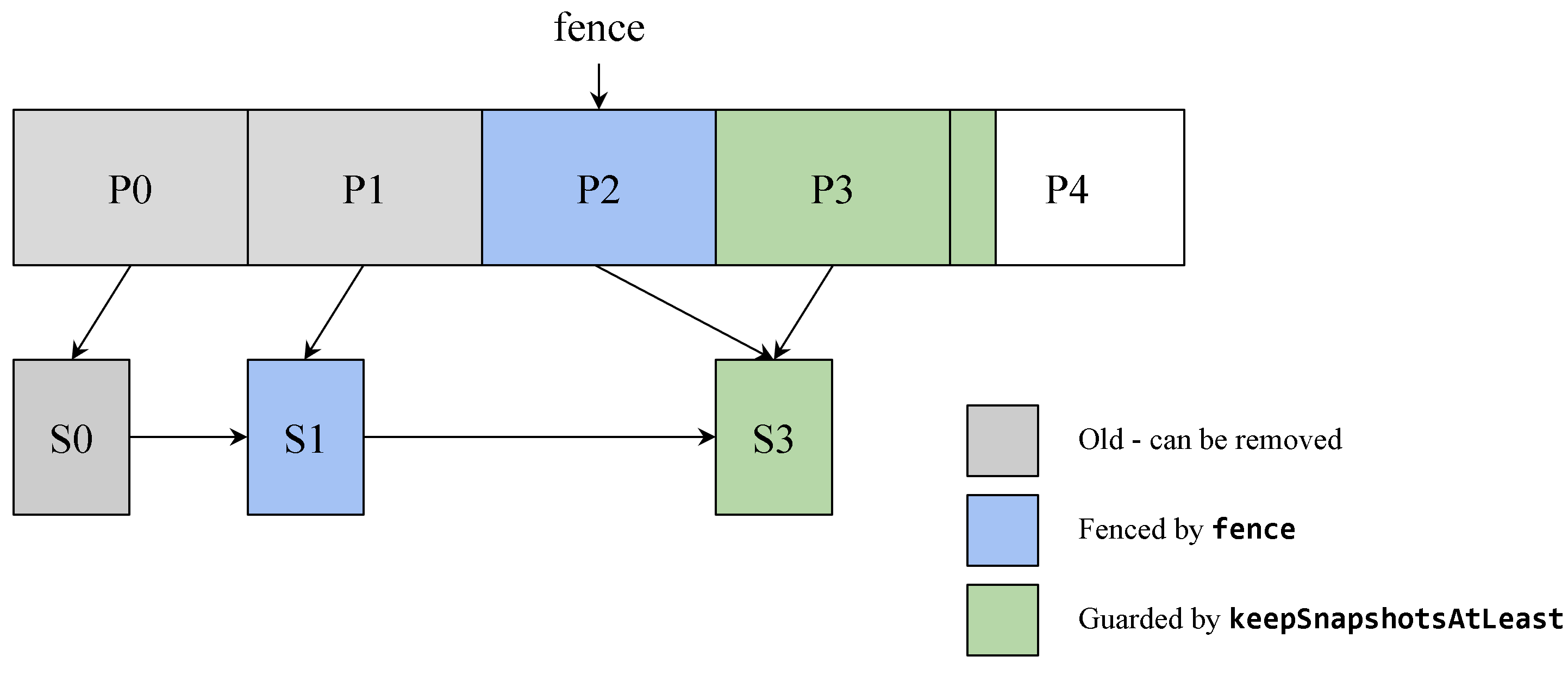
Diagram
The following diagram shows the effect of journal compaction, including warehouse fencing:
Managing Data Partitions and Snapshots
If you do not require the whole history, including “empty orders”, to be preserved on a disk, you can configure the Compactor to delete data partitions that are not directly needed for Ember operation using the deletePartitions setting.
Snapshots are deleted in sequential order. Partitions are also deleted in sequential order but only when at least one snapshot is deleted.
Fences
A fence is a file used to determine whether snapshots and partitions can be deleted or not. Currently, there are only two service types that use this feature: Warehouse and DropCopy.
If the fences are not explicitly specified, the service discovers them via the configuration. A service restart is required when Warehouse/DropCopy are added or removed.
If you delete services from the config, ensure that you also delete the corresponding fence files manually.
Journal Archiver
Please note that while Ember is running, the only way to create an archive of the journal is by using the Archiver tool.
The Archiver tool compresses and decompresses a journal into and from an archive format. Within the Ember distribution package, you can find two scripts: journal-compress and journal-decompress:
journal-compress- This script takes the earliest snapshot with partitions and compresses them into an archive namedjournal.archive, stored in the Ember work directory.journal-decompress- decompresses the contents ofjournal.archiveback into the journal directory. When usin this tool, ensure that the journal directory does not exist prior to decompression.
For more information, visit the journal-compress & journal-decompress tool page.
Periodic Flush
Ember employs memory-mapped files for writing journal data. The operating system ensures that data is flushed to disk even if the Ember process crashes. However, in the event of a sudden server shutdown, such as a sudden server death, Ember might encounter data loss for a recent portion of journaled data.
To address this, one potential solution is to force a flush of every trading signal to disk prior to processing. This "force flush" can be time-consuming and is generally avoided by latency-oriented systems due to the performance impact.
An alternative approach is the implementation of a periodic journal flush:
# Interval to force a periodic journal flush (or 0 = disable periodic force flush)
journal.forceFlushInterval = 15s
We advise against using this feature in cloud environments or reliable data centers that provide redundant power.
For practical alternatives to periodic flushing, consider the following options:
- Running an Ember cluster - Performs synchronous replication of trading signals. While this alternative raises operational costs, it provides a hot failover mechanism in case of primary server loss.
- Running an asynchronous Journal Replica service - Refer to the Ember Disaster Recovery document for details on implementing this service.
- Running a low latency data warehouse - (For example, streaming trading activity to TimeBase located on a separate server). In the event of journal data loss, data can be recovered using the journal-import tool.
Human-readable Format
To facilitate human readability, you can employ two scripts: journal-to-json for converting binary journal data to JSON format, and journal-from-json for reversing the process.
Note that these tools rely on the EMBER_WORK (or EMBER_HOME) environment variables to locate journal. The only command line argument required is the destination JSON file (or the source JSON file accordingly).
Data Warehouse
For long term storage, it is possible to stream journal entries into data warehouse solutions like ClickHouse. Refer to the Streaming Ember Messages to ClickHouse document for more information on this process.
Load Test
In this section, we present statistics obtained from a prolonged stress test lasting 20 days. The stress test was conducted on a Matching Engine that received simulated client load. Throughout the test, the system recorded 100 billion trading requests and experienced a variety of trading workflows, including fills, cancellations, and rejects.
Here are the statistics recorded:
119,453,646,240 - Ember.Requests
155,554,802,873 - Ember.Events
92,230,355,523 - Ember.TotalOrders
49,095,984,555 - Ember.TotalTrades
Over the course of this test, the system processed 50 terabytes of journaled data:
ls -l /deltix/emberhome/journal/home
-rw-r--r-- 1 centos centos 1073741824 Apr 30 16:48 data50980
-rw-r--r-- 1 centos centos 847249408 Apr 30 16:49 data50981
-rw-r--r-- 1 centos centos 1792 Apr 30 16:49 meta
-rw-r--r-- 1 centos centos 33401936 Apr 30 16:48 snapshot50980
Real-Life Example
This example was taken from a Market Maker client. The Journal in this instance contains approximately 2GB of data:
11/20/2020 11:42 AM 1,073,741,824 data0
11/20/2020 11:42 AM 1,073,741,824 data1
11/20/2020 11:42 AM 50,331,648 data2
11/20/2020 11:42 AM 1,792 meta
4 File(s) 2,197,817,088 bytes
During startup, Ember took around 25 seconds to read the journal:
23 Nov 17:49:15.804 INFO [trade-engine] EMBER is loading journal. Snapshot: no.
[…]
23 Nov 17:49:40.342 INFO [trade-engine] EMBER has loaded journal. Messages: 9187841.
Here's another snapshot from a production environment, taken from one of the clients. In this case, the system generated 7592 data partitions. Partitions of around 1GB each were filled in approximately 30 minutes:
drwxr-xr-x. 6 dx_support dx_support 198 Jul 23 00:11 ..
-rw-r--r-- 1 dx_support dx_support 408998768 Jul 23 13:15 snapshot7590
-rw-r--r-- 1 dx_support dx_support 1073741824 Jul 23 14:00 data7591
-rw-r--r-- 1 dx_support dx_support 398382112 Jul 23 14:00 snapshot7591
-rw-r--r-- 1 dx_support dx_support 1073741824 Jul 23 14:46 data7592
-rw-r--r-- 1 dx_support dx_support 1024 Jul 23 14:46 fence-warehouse-marketmaker
-rw-r--r-- 1 dx_support dx_support 395913832 Jul 23 14:47 snapshot7592
drwx------ 2 dx_support dx_support 161 Jul 23 14:47 .
-rw-rw-r-- 1 dx_support dx_support 1792 Jul 23 14:51 meta
-rw-r--r-- 1 dx_support dx_support 159383552 Jul 23 14:51 data7593
Latency/Throughput test
The following illustrates journal state during "latency-new" test of NME matching engine at 235K order requests per second. We can see gigabyte data partitions fill in 12-15 seconds.
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:30:32 data320
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:30:44 data321
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:30:55 data322
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:31:07 data323
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:31:19 data324
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:31:30 data325
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:31:42 data326
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:31:54 data327
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:32:05 data328
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:32:17 data329
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:32:29 data330
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:32:41 data331
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:32:52 data332
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:33:04 data333
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:33:16 data334
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:33:28 data335
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:33:39 data336
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:33:51 data337
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:34:02 data338
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:34:14 data339
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:34:26 data340
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:34:38 data341
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:34:49 data342
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:35:01 data343
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:35:12 data344
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:35:30 data345
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:35:41 data346
-rw-r--r-- 1 1666 1666 1.0G 2025-09-10 17:35:53 data347
-rw-r--r-- 1 1666 1666 16M 2025-09-10 17:35:53 data348
-rw-r--r-- 1 1666 1666 1.8K 2025-09-10 17:35:35 meta
-rw-r--r-- 1 1666 1666 2.0G 2025-09-10 17:31:42 snapshot319
-rw-r--r-- 1 1666 1666 2.1G 2025-09-10 17:32:54 snapshot325
-rw-r--r-- 1 1666 1666 2.1G 2025-09-10 17:34:19 snapshot332
-rw-r--r-- 1 1666 1666 2.2G 2025-09-10 17:35:42 snapshot339
-rw-r--r-- 1 1666 1666 256 2025-09-10 17:35:43 snapshot346.8fbd4010f0e5076b.temp
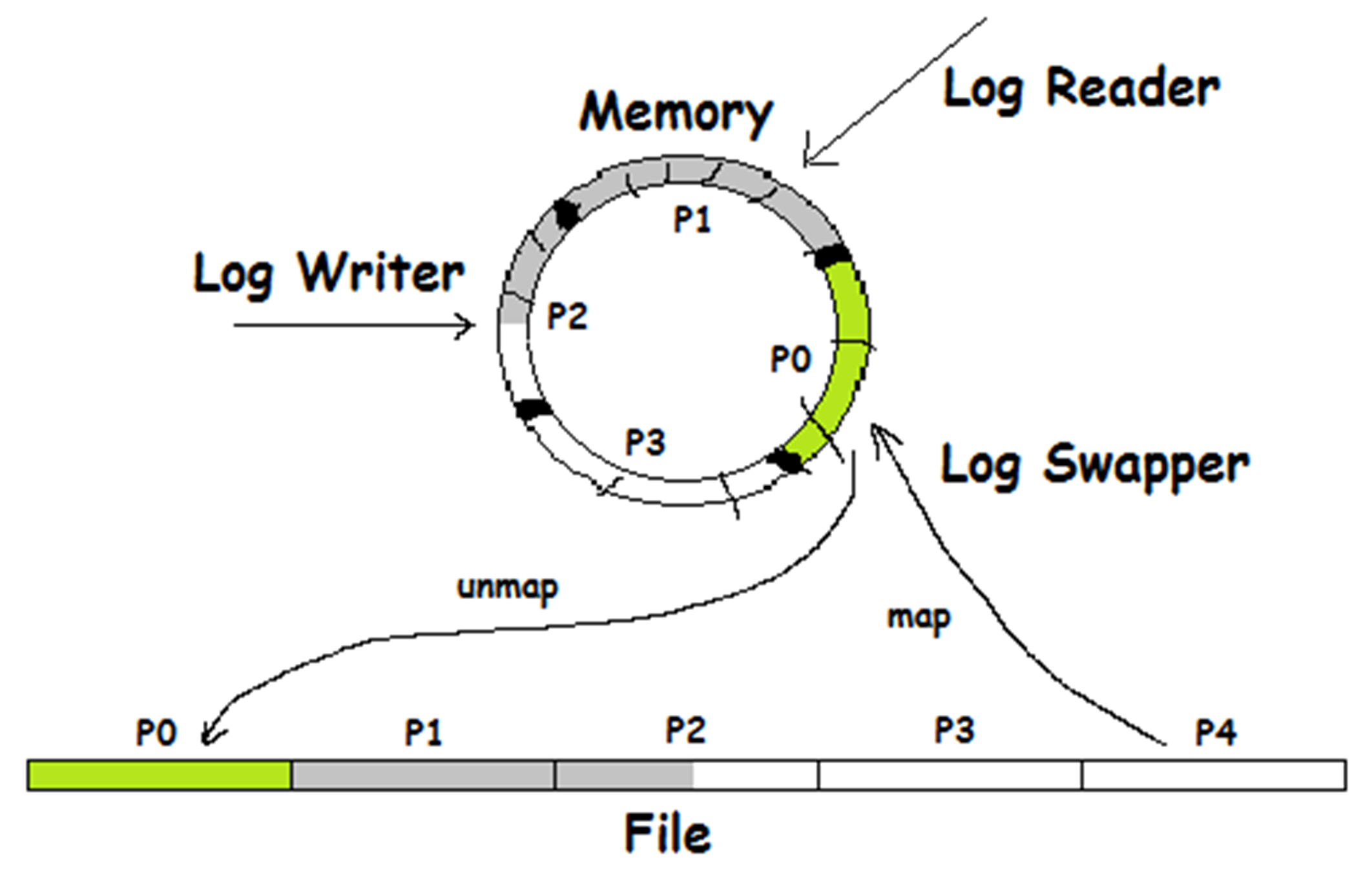
Appendix A. Early Journal Model
Prior to Ember 1.0, a simpler version of journaling was used. While not exactly the same, this early diagram can illustrate how Ember works with journal files.