Ember Disaster Recovery
This document provides an overview of the Disaster Recovery (DR) approach for the Ember.
Disaster Recovery vs. Cluster
For clients seeking High-Availability (HA), we recommend setting up Ember Cluster mode. Please refer to the Ember Cluster documentation for more information.
Disaster Recovery and High-Availability are not mutually exclusive; they can complement each other. Clients have the option to implement both approaches.
The following table compares the two operation methods:
| Approach | Ember Disaster Recovery | Ember Cluster |
|---|---|---|
| Scope | Multiple data centers, possibly in different regions | Single data center, same network |
| Recovery Time Objective | 1-3 hours | Seconds to a few minutes |
| Data Replication method | Asynchronous, Batched | Synchronous |
| Data loss in case of a disaster | Dependent on batch size and replication method. May lose several minutes of recent trading activity. | No order loss for trading requests, possible loss of exact information about each trade (only cumulative/average trade information may be recovered). |
| Operational complexity | Manual failover. Some DevOps work to set up file replication. Some upfront cost to set up journal replicator. | Fully automated failover. Additional cost to maintain and host additional cluster services (Aeron, Zookeeper, Journal sync). |
| Hardware/ Cloud Hosting Cost | DR location can provision expensive resources on demand (in case of failover). | Requires 2x resources compared to a single-instance Ember setup. |
Highlights
Ember uses the following data:
- Configuration Files - These include deployed algorithms and configured connectors, such as connection parameters to downstream execution venues or data warehouses. The location of these files is defined using the
EMBER_WORKenvironment variable. - Operation Files - These encompass Ember Journal, Recent Market Data, FIX Drop Copy Session states, and more. The location of these files is defined using the
EMBER_WORKenvironment variable.
The Ember Journal is the source of truth for trading states, encompassing orders and positions.
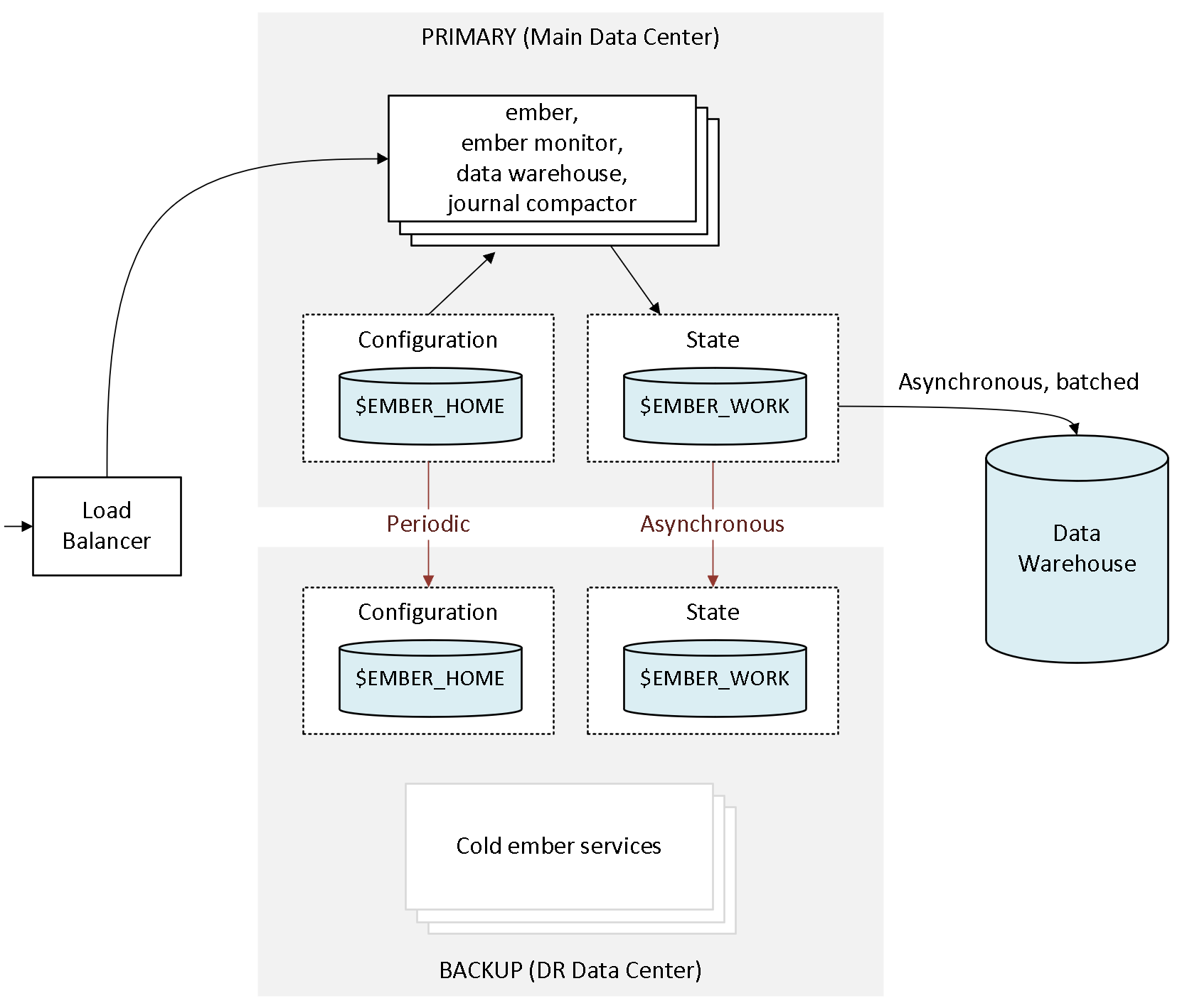
The following diagram illustrates DR data replication:
General Suggestions
- Scheduled backups for Ember configuration files - Establish a regular backup routine for your Ember configuration files, which are identifiable by the
EMBER_HOMEenvironment variable. The frequency of these backups depends on your production deployment practices. For many production environments, these configuration files don't change frequently. Consider integrating production configuration backups into your environment upgrade process. - Frequent backups of the Ember work directory - Regularly back up the Ember work directory, which is identified by the
EMBER_WORKenvironment variable.- To reduce the risk of inconsistent backups of Ember Journal, use the
ember-journal-replicatool or thejournal-compressandjournal-decompresstools.
- To reduce the risk of inconsistent backups of Ember Journal, use the
- Implement data warehouse replication - Consider implementing data warehouse replication mechanisms when applicable. For example, use an S3 data warehouse or configure a replica for SQL Server RDS (Relational Database Service).
- Training for Ember Disaster Recovery (DR) - Provide comprehensive training for your operations team on Ember DR procedures. This ensures that the team is well-prepared to execute effective DR measures when required.
Ember Directory Structure
Home Directory
The home directory serves as the respository for all Ember configuration files. For example, the main configuration file, ember.conf, is loaded from this location. The home directory is defined using the EMBER_HOME environment variable, with the user's home directory being the default.
These are some additional artifacts you may find in the Ember Home directory:
- Additional configuration files, such as those used for Trading Connector configuration. For example, the fix-connections.conf file.
- Ember Monitor configuration, typically stored in the application.yaml file used by the Spring Boot web application.
- User Access Control configuration files including files like uac-file-security.xml and uac-access-rules.xml. See the Ember Monitor Configuration Guide.
- Logging configuration, generally found in the gflog.xml file.
Work Directory
During runtime, Ember produces a range of files and directories, listed below:
- The Ember Journal (also referred to as the Transaction Log). Lives in the
$EMBER_WORK/journalsubdirectory. It is important to note that the Ember Journal directory can grow considerably in size, even when a retention/compaction policy is configured. By default, each data partition file is 1GB. Ember uses memory-mapped files to write data partitions. Using external tools like rsync might lead to inconsistent snapshot copies of data partitions while the live Ember process is modifying the data. For consistent snapshots, we recommend using the Journal Archiver. - Log Files usually found in the
logssubdirectory. - FIX Message Logs organized into one subdirectory per connector.
- Performance Counters usually kept in the counters.data file.
- State information for FIX Drop Copy sessions.
By default, the Ember work directory is the same as the home directory. However, by using the EMBER_WORK environment variable, you can redirect the work directory to an alternate location.
We recommend separating the work and home directories for the following reasons:
- Work directories typically require faster disk drives, such as SSDs or NVMe drives.
- Home directories may be placed on a read-only drive to avoid unauthorized configuration changes.
- When running under Docker container,
EMBER_WORKcan be mounted as a persistent writable volume.
Journal Corruption
While Ember Journal has been carefully tested and stress tested, special circumstances like sudden power loss or a disk failure may lead to corruption. Although self-healing logic executes on Ember startup, in special cases you may need to run the following tools:
journal-recover- This tool attempts to recover the Ember Journal in especially difficult cases. It may ask the user for confirmation in some questionable cases, such as when truncation is the only obvious option. For more information on the tool, visit thejournal-recovertool documentation. For more information on Ember Journal, see the Ember Journal documentation.journal-transform– This tool can be used to edit the journal, for example, to remove “poisonous” messages. For more information, visit thejournal-transformtool documentationjournal-to-jsonandjournal-from-json– This pair of tools provides another way to inspect and edit the journal. For more information, visit thejournal-to-jsonandjournal-from-jsondocumentation
Journal Archiver
Please note that while Ember is running, the only way to create an archive of the journal is by using the Archiver tool.
The Archiver tool compresses and decompresses journal data into and out of an archive format. Two scripts, journal-compress and journal-decompress, are included in the Ember distribution package:
journal-compress- This script takes the earliest snapshot with partitions and compresses them into an archive namedjournal.archive, which is stored in the Ember work directory.journal-decompress- This script decompresses the contents ofjournal.archiveback into the journal directory. Prior to using this tool, ensure that the journal directory does not exist.
For more information, visit the journal-compress and journal-decompress tool documentation.
Data Warehouse
The Ember provides several connectors to various data warehouse systems. Currently our supported systems include TimeBase, ClickHouse, Amazon RedShift, Amazon S3, and Amazon RDS SQL Server. This list can be extended upon customer request.
Data warehouse connectors can operate in both micro-batch and near-real-time modes. This versatility makes it possible to use data warehouses as DR data references, particularly for recent trade information.
For more information, see the Data Warehouse Pipelines documentation.
Asynchronous Replication
An asynchronous replication mechanism is facilitated through the following set of Ember tools:
- Journal Replica Server - This service runs in tandem with the main Ember server. It is responsible for serving an asynchronous replica of the Ember journal.
- Journal Replica Client - This service runs at the disaster recovery (DR) location, this service is responsible for storing a replica of ember journal to local disk. Communication between the main server and the DR location is done over TCP.
When the main and DR locations are connected over public internet, we recommend encrypting this connection using SSL termination software like STUNNEL.
Journal Replica Server
The Journal Replica Server service is defined by the script journal-replica-server and requires access to the $EMBER_HOME and $EMBER_WORK directories of the main Ember process.
It uses the following configuration stanza in $EMBER_HOME/ember.conf:
replication {
host = "0.0.0.0"
port = 8977
}
Here is the typical output of this service upon startup:
$/deltix/ember/bin/journal-replica-server
2022-12-05 23:21:50.836717500 INFO [replication-server] Replication: Creating fence. Fence partition: 0. Fence file: /deltix/emberwork/journal/replication.
2022-12-05 23:21:50.885587100 INFO [replication-server] Replication: Session is up. Local address: 0.0.0.0:8977. Fence partition: 0.
Journal Replica Client
The Journal Replica Client service is defined by the script journal-replica-client and requires access to the $EMBER_HOME and $EMBER_WORK directories of the DR site. The Ember service must not be running on the DR location when this tool is replicating the journal.
For synchronous replication, consider using the Ember HA Cluster.
This tool uses a symmetrical configuration stanza in $EMBER_HOME/ember.conf:
replication {
host = "ember1" # DNS name of the main Ember location
port = 8977
}
Here is the typical output of this service upon startup:
$/deltix/ember/bin/journal-replica-client
2022-12-05 23:28:50.058947000 INFO [replication-client] Found existing journal (Created 2022-11-21T18:09:39.231Z, position 2768)
2022-12-05 23:28:50.059038800 INFO [replication-client] Replication: Session is up. Remote address: ember1:8977.
2022-12-05 23:28:50.122600200 INFO [replication-client] Replication: Session is connected.
2022-12-05 23:28:50.145309600 INFO [replication-client] Received replication response: {"$type":"ReplicationResponse","flags":2,"version":26,"segmentCount":8,"segmentSize":8388608,"partitionSize":1073741824,"creationTime":1669054179231,"position":2768,"ok":true,"text":"Ok"}
2022-12-05 23:28:50.160886100 INFO [replication-client] Replication: Syncing partition. Partition: 0. Position: 2768. Backlog: 0 B.
Just as the journal-compaction tool is recommended to run on the master location, we recommend running this tool on the DR site.
By default, the Journal Compactor ensures it tails the main Ember service by:
- Waiting for Ember to acquire a special file lock in the
$EMBER_WORKdirectory. - Waiting for Ember to emit regular heartbeats (based on the Counters feature).
- Waiting for Ember to acquire a special file lock in the
Starting with Ember 1.14.205, the Journal Replica Client acquires the file lock (acting as the main journal writer), but does not emit heartbeats. If you're using Ember 1.14.205 or later, run the Journal Compactor with the
-skip-heartbeatoption.For older versions of Ember, use the
-nowaitoption to skip waiting for Ember entirely.
Healthcheck port
When Journal Replica Server is running behind load balancer (e.g. Amazon NLB) you may want to configure it to expose TCP port for load balancer healthcheck:
replication {
host = "ember1" # DNS name of the main Ember location
port = 8977
healthcheckPort = 8978
}
In this case you should see additional logging on the service startup:
2025-06-26 22:09:46.884 INFO [Thread-0]: Network Healthcheck is running on: /0.0.0.0:8978.